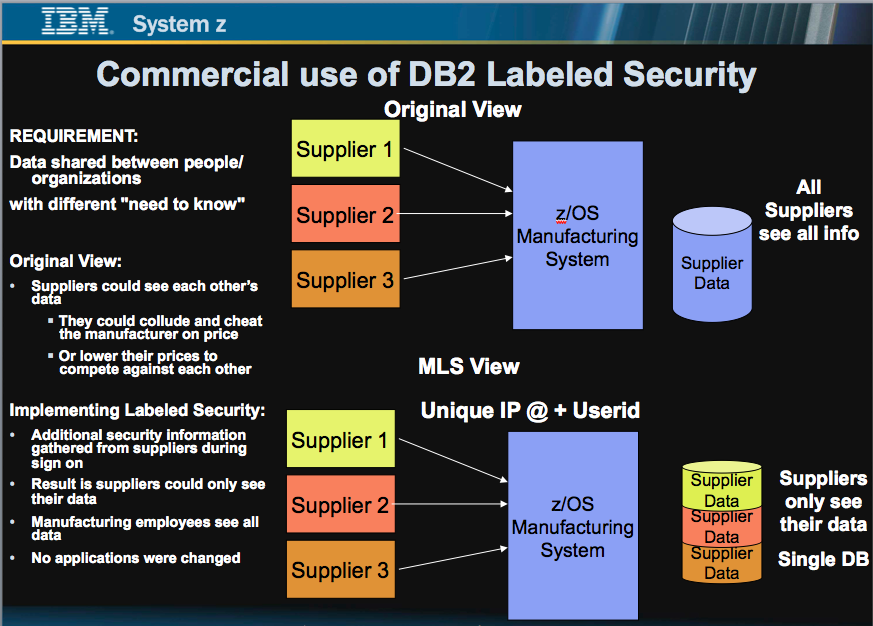
I recently was given a list of emerging technologies and asked how the mainframe, and in particular, z/OS, is relevant to those technologies. It’s a great question. Unfortunately, it’s important to understand the source and motivation of the question. Sometimes, the questioner is looking for an excuse to bury the mainframe. They’d have the unintended consequence of not finding or looking for synergy with the mainframe. In other cases, there is genuine curiosity. I’m going to go with curiosity in this case and give my best effort to respond.
Systems of Record are where data resides. Systems of Engagement are where information is accessible to end users. In many cases, PC systems are both a System of Record and a System of Engagement, so there is a thought that these “commodity” systems are “good enough” to handle all workloads. That couldn’t be further from the truth. Complexity, scale, security and business resilience are some of the problems that occur when commodity devices become the sole “solution” to problems. However, there is another major problem – operational silos. This occurs when one organization solves “one problem” while another organization solves and manages another business problem. Complexity and risk occurs when multiple organizations depend on each other to replicate data or share data for different purposes. This is where system security and resilience are at risk. It also requires duplication of data and duplication of effort to manage that data. Any duplication adds to costs.
I like a different approach. It’s based on leveraging the best of all technologies: commodity front end devices, such as PC’s, Smart Devices and the Internet of Things (definition later); Commodity servers for data transformation and hosting applications; large-scale servers for hosting and managing access to data, including a large amount of data manipulation and processing. In this hybrid environment, the goal is to bring the applications to the data. There will never be a single copy of data (e.g. backups, disaster recovery, cloning), nor will there ever be a single server to process that data. However, by sharing data and reducing copies, a simpler deployment model is possible. In addition, cross-platform security and resilience should be a part of the solution so that data is processed on a “need to know” basis and applications are highly available, end to end. It doesn’t make sense to have a back-end server (System of Record) that is 99.999% available if the front end infrastructure (System of Engagement) is full of availability and security issues. Our goal is to provide an end to end deployment infrastructure that provides efficient integration across the components and technologies necessary to meet a business’ workload needs. In the process, the business or government agency should dramatically reduce operational cost and complexity, while improving security and business resilience. This infrastructure can meet or exceed service level agreements and provide investment protection for the future.
Given the above context, here are a couple of emerging technologies and my view of where a hybrid approach can help them or not. I say my view, but the reality is, my good friend, George Thompson of IBM, provided the first pass at this list. We’ve been collaborating for many years. In my role as a consultant to Vicom Infinity, George is the principal IBMer I’ve been working with toward challenging customers to save $2 million dollars on IT expenses. So here we go:
1. Digital Security
There are many ways to look at this. But most importantly, collaboration is king. There will never be a “Single Sign On”. However, there are multiple sign ons with shared credentials. A good example of that is Apple has the same sign on credentials for it’s Apple Store, iMessage and iCloud, among other applications. But taking it a step further, they’ve introduced biometrics through finger print readers on their smart devices. Other forms of multi factor authentication can be deployed. There needs to be a source for “the truth”. There are several large banks and governments that have leveraged z/OS RACF for hosting digital certificates as the basis for authentication across applications and devices. One bank has stated that they avoid $16 million in annual license fees from third parties by hosting and managing their own digital certificate infrastructure on their existing mainframes.
Beyond authentication are digital footprints necessary for forensics utilized for Cyber security fraud, theft and rogue insider activities tracing. There are so many products that can collect logs and monitor those footprints. z/OS and Linux on z have been leveraged as collectors of these logs to allow for processing across workloads and to look for anomalies that might not be detected otherwise, if each different organizational unit was processing the request. The New York Police Department (NYPD) deployed a product from Intellinx that captured end-user activities across their agency. Up until that deployment, each of their 30+ applications had a unique home-grown audit capability. Intellinx enabled them to eliminate the “silo’ed” audits and combine them into a single commercial off the shelf (COTS) product. It also allowed them to find anomalies across the entire application suite that may not have been easily detected, manually, by their silo’ed offerings.
2. Virtual Personal Assistant
Cognitive computing is evolving rapidly. Speak into your phone or tablet. Ask a question or request a task be executed and your “wish” becomes their “command”. Simple requests are executed on the device itself (e.g. call a person). But many requests go to a central “cloud based” service. The request gets parsed for context, a knowledge base is queried and the result is provided to the requestor.
I don’t see the mainframe “operating” the Virtual Personal Assistant, at this time. However, I do see the mainframe as a source for the knowledge base for a wide variety of applications. If you ask to query your account balance, does the bank make a copy of that “up to date” business record and send it to the VPA server? No. The VPA is the System of Engagement. It translates the request into a query. The query is sent to the relevant server which processes the request and sends the results bank. The VPA then translates that into spoken word or some form of viewer by launching a device app to display the results. These are not mutually exclusive processes.
Going back to Digital Security, the back end server that processes the query could use the Digital Security provided by the previous authentication of that device. It could also send a challenge request directly to the device, as a form of multi factor authentication, to ensure it wasn’t a fraudulent request, such as a phishing attempt. Collaboration is critical.
3. Smart Workspace
I found an interesting definition at a Johnson Controls website. What was most interesting to me is that I know of Johnson Controls from their utility infrastructure monitoring devices, also known as SCADA or system control and data acquisition devices (e.g. thermostats, system monitors). And that leads me to think of the security of those devices. But I digress. Their vision is around Social Computing, Mobile and Collaboration so that the workplace of the future is a virtual office where you feel a sense of community with your peers rather than feel isolated. This includes document collaboration, video and screen sharing, smart walls/boards/screens that are touch sensitive. These can all be considered the System of Engagement. What’s the mainframe and z/OS role? The source of the files/documents. The authentication server that coordinates the integration of each of the pieces of this “virtual community”. The fault tolerant backup of the critical data elements. The workflow scheduler that “turns on” and coordinates the myriad of parts of a very large virtual community.
4. Software-Defined Anything (SDx)
The idea here is that instead of physical servers and physical devices or appliances, the IT world evolves to virtual appliances and virtual application images. The mainframe can be viewed for three major virtualization capabilities.
1. Logical partitioning – PR/SM LPAR – that enables the mainframe to be carved up into separate entities. This really is a physical partitioning, though and probably doesn’t apply.
2. z/OS – originally known as MVS for Multiple Virtual Storage – for it’s ability to run multiple applications and data types within the same operating system image.
3. z/VM – with its ability to run multiple operating systems and therefore, multiple application servers simultaneously and on demand.
Within z/OS and z/VM, there is software defined networks, memory and storage that enable direct sharing between workloads. In some cases, with new hardware definitions, only pointers to data are shared between applications to dramatically improve performance latency, reduce virtual and real memory and improve security, resilience and scale of the end to end workload.
That’s not to say that z/OS and z/VM are the answer to Software Defined Anything. The Anything is workload and solution dependent. These systems can participate effectively as part of a bigger solution to reduce costs and improve the solution qualities.
5. Affective Computing
This is an area that probably doesn’t have direct ties to a mainframe. As defined in wikipedia: it’s about computer science, psychology and cognitive computing. Think about robots that attempt to mimic human activity.
I don’t see arms and legs protruding from an IBM mainframe nor a mainframe chip within a robot, yet. I still see mainframe connections. One is through security. These robots need to be smart. They need to get their “smarts” from some source. That source needs to be secure. Authentication must occur. The robot will then “do things”. Are they transactional? These are things that can be done with a mainframe.
6. Neurobusiness
The Gartner Group definition is “capability of applying neuroscience insights to improve outcomes in customer and other business decision situations.” To me, insights equals analytics. Analytics on the mainframe and z/OS is fantastic. Why? It’s got the data. There are many businesses that look at trends, anomalies and other analytic insight to improve sales, identify fraud detection, forecast future trends and leverage existing data and analytic capabilities on the mainframes. There are also businesses that are running analytics on commodity servers against commodity hosted data and joining those results with analytics run on mainframes against mainframe data.
The definition, looking at other sources, is applied to training and decision making.I don’t necessarily see the mainframe participating in that aspect.
7. Prescriptive Analytics
Described by wikipedia as the third and final phase of business analytics (BA) which includes descriptive, predictive and prescriptive analytics. Vendors such as SAS and IBM’s SPSS have been on z/OS for many years. SAS has described the lack of value of “looking in the rear view mirror” rather than looking ahead to how you can get value for many years. The mainframe has plenty of the business data. These vendors have brought the applications to the data in order to gain the insight and provide the business value.
8. Data Science
A pseudonym for analytics. There are multiple parts of analytics:
- The data.
- The application that analyzes the data.
- The application that presents the results.
The mainframe has long been excellent at hosting and processing the data. The System of Record. Data visualization is the role of the System of Engagement and commodity hosted devices. If a business wants to “copy the data” in batch, host it on a commodity server and then process it and display it on a commodity device, that’s their prerogative. But what does that cost them?
- Time – necessary to make the copies.
- Network – bandwidth to make the copies.
- Storage – to host temporary and production copies of the data.
- Compute Capacity/Scale – that’s used to move the data, instead of processing it.
- Environmental – energy, floor space and cooling for the copies of data.
- Money – for all this “excess” capacity.
- And lest we forget – Security – to make sure that the “need to know” aspects of the particular data copied is handled the same, regardless of where it resides and
- Resilience – back up capabilities for all the extra servers and data.
Needless to say, many businesses are leveraging near real-time analytics against the System of Record hosted on a mainframe and leveraging the best capabilities available on mobile devices and PC’s for the visualization of the results.
9. Smart Advisors
This is a System of Engagement. It could be a human or it could be the dissemination of data to a human. This is not the role of the mainframe. That Advisor needs to get its “smarts” someplace. As demonstrated earlier, the mainframe, z/OS, their data and their analytic processing can contribute to those “smarts”.
10. Speech-to-Speech Translation
This is a System of Engagement. Not necessarily the role of a mainframe. Once it’s translated to actions, the mainframe is happy to oblige and process the request. It can also work to ensure the authentication of the user/device requesting the translation, when necessary.
11. Internet of Things (IoT)
This typically refers to the myriad of new devices that are being made accessible via the Internet, e.g. Home appliances, Light bulbs, cars, cameras, etc. For this reason, the Internet naming convention was running out of addresses (IPv4), so a new addressing convention, IPv6 was created to handle the demand. Most of these devices are Systems of Engagement. They need to securely access Systems of Record.
The mainframe and z/OS have introduced IPv6 to enable direct connection to those devices. As defined earlier, the security of those devices and the monitoring of them can be handled on a mainframe. These devices are not islands, nor is the mainframe. They can easily collaborate to bring the best of all worlds into new solutions and other emerging technologies. IBM recently launched a foundation for the Internet of Things.
12. Natural-Language Question Answering
At the front end, this is a System of Engagement. To get the answers, Systems of Engagement and knowledge bases are required. I don’t envision the mainframe doing the natural language parsing, but I certainly envision their role in preparing the answer and securing the connection from end to end.
13. Complex Event Processing (CEP)
I love math. Patterns, Fractals, Recursion. Macro and Micro views. Computers are outstanding at repeating patterns. Many of the problems that I see in contemporary society are because we are too close to a problem. If you step back a little, a look at “the bigger picture”, you can see patterns repeated.
Event processing is like a Dispatcher. Every operating system has a dispatcher at a kernel level. Many operating systems cannot dispatch disparate work simultaneously because those systems don’t know how to balance the needs of the many and prioritize them against the needs of a few. Deadlocks, overcommitment and race conditions occur for unsuccessful systems. z/OS and the mainframe have demonstrated excellent capabilities for avoiding these issues and provide granularity, at a business level, for balancing the processing needs. More importantly, many years ago, they created workflow processing that deals with the success or failure of prior tasks to determine the next task. At a micro level, z/OS has been executing Complex Event Processing for decades.
Now, the term applies to end to end business solutions that include multiple Systems of Engagement and multiple Systems of Record. There are several middleware solutions that enable the mainframe and z/OS to participate and to manage CEP and be managed by CEP across a disparate group of systems and devices.
14. Big Data
This is primarily dealing with the System of Record and the analysis and processing of the data within Systems of Record. z/OS and the mainframe have demonstrated the ability to process their own data, the data of other systems and to have their data processed by other systems.
Security, storage management and resilience of the data on both z/OS and other servers can be managed from z/OS as well.
15. In-Memory Database Management Systems
As a database, this is a System of Record. For many years, middleware, such as CICS for z/OS, has provided an in-memory database management system. New applications are looking for SQL and other industry standard interfaces to these in memory databases. z/OS and the mainframe are capable of meeting these needs and working in collaboration with other systems that provide these capabilities. In addition, z/OS and the mainframe can provide authentication and resilience services for these databases.
16. Content Analytics
Content analytics is the act of applying business intelligence (BI) and business analytics (BA) practices to digital content. Companies use content analytics software to provide visibility into the amount of content that is being created, the nature of that content and how it is used.
This is another area of System of Record. z/OS and the mainframe have a variety of middleware associated with content management, including archive functions for media streams, documents, and other non-relational data types. In turn, there are analytic solutions available on the mainframe and off it to process that data.
17. Hybrid Cloud Computing
By definition, this includes internally managed clouds in concert with externally accessed clouds by a business or agency. zEnterprise is the premier Hybrid Cloud platform supporting Public, Private and Community clouds across heterogeneous architecture and supporting many cloud infrastructures including OpenStack. Enough said.
18. Machine-to-Machine (M2M) Communication Services
This is related to the communication between the devices associated with the Internet of Things and the success of IPv6. As stated earlier, the mainframe and z/OS are already enabled for this form of communication.
19. Cloud Computing
Somewhat redundant with the Hybrid cloud computing item above, both z/OS and the mainframe provide cloud hosting capabilities. Allen Systems Group’s Cloudfactory/Mainframe has enabled much of the functionality of z/OS to be accessed and provisioned via an interface that is similar to Amazon Web Services.
20. Gesture Control
By definition, this is a human computer interface and therefore a part of the System of Engagement. This is not a role that I envision the mainframe to undertake. The gestures will be interpreted and actions are taken, as a result. Some of these actions may be directed toward transactions or applications hosted on the mainframe and z/OS.
21. In-Memory Analytics
There are several approaches to solve this problem. Architecturally, there are some valuable differences.
- For the x86 and Power architectures, IBM has delivered:
IBM’s DB2 10.5 with BLU Acceleration, typical queries in an analytics workload have been shown to be more than 1,000 times faster than other leading databases. Innovations in BLU Acceleration include:
· ‘Dynamic in-memory” columnar processing providing not only dramatic analytics performance – up to 25 times faster -– but also the ability to scale for expanding Big Data needs without the limitations imposed by traditional in-memory systems.
· “Load and go” simplicity which allows clients access to blazing-fast analytics transparently to their applications, without the need to develop a separate layer of data modeling.
· “Parallel vector processing” for high-performance data analysis in parallel across different processors.
· “Actionable compression,” providing as much as 10 times storage space savings where data no longer has to be decompressed to be analyzed.
This DB2 is typically called LUW – Linux, Unix and Windows version. In this case, the BLU acceleration is not available on Linux for System z implementation of DB2. However, through database connection middleware, the z/OS data can be accessed by this product.
- Hadoop is an open source implementation of a large scale analytic server that has been deployed on the mainframe by IBM and by Veristorm’s zDoop offering. This can leverage most of the z/OS System of Record databases and make them accessible to the Hadoop File System running on the mainframe or other Hadoop servers.
- Another hybrid implementation is the IBM Database Analytics Accelerator (IDAA). This is a co-processor that works with flash (memory) copies of data on z/OS and can process a query 1000x faster that z/OS might on it’s own. There are several operational benefits to this approach:
- Security – the authentication, access control and logging are all done in the context of the z/OS user that initiated the query request. This simplifies audit and analysis of user behaviors.
- Latency from OLTP to Analytics – It provides near real-time access provided to transactional data where other systems might be using a copy of time that takes a lengthy time to unload, transfer and reload prior to its availability for analytic processing.
- Cost – it provides commodity analytic server costs without the need for extra management as an independent server instance and the costs of security and resilience associated with that.
22. Activity Streams
This are generated at a System of Engagement. Activity streams are generally associated with Social Media applications. There are a number of products that will take these feeds and coordinate them across Social Media platforms. I am not aware of any of them running natively on z/OS, though I do believe the IBM Connections can run on the mainframe. Some of the z/OS management activities can be processed as activity streams and posted to social media. This is valuable where an internal wiki might be used to manage or display mainframe system status.
23. Speech Recognition
Speech recognition research and development has been going strong at IBM for almost 50 years. Throughout that time, more than 200 IBMers have contributed to the significant advancements in this field. That being said, it is a System of Engagement.
Middleware is available, as part of multi factor authentication, to leverage speech recognition and patterns as a login method that can be passed to the mainframe. Speech recognition middleware can also be leveraged to begin applications or start tasks on z/OS and the mainframe. Customers have used these techniques to simplify the human interface to z/OS.
That’s the end of the list I received, but not the end of my thoughts on Emerging Technologies.
The Evolution of the Mainframe.
Database Processing.
By nature, database processing deals with the System of Record. IBM’s DB2 platform was originally deployed in the early 1980’s after a successful research product. Later, on a separate code base, the DB2 for Linux Unix and Windows was created with a similar programming interface to the mainframe version. Mainframe customers demand consistency and a legacy that they can count on. Once implemented by IBM or other vendors and then successfully used in production by a customer, the customer expects that code to run “forever”. I can tell you that I’m working with a customer now whose original code was written in 1969 and they are many generations of hardware and software old and out of service, but they are still working with integrators to keep it running.
With those requirements in mind, IBM has developed a philosophy that many of the new technologies will be deployed on the DB2 LUW version first. If successful, that functionality will be later integrated into the DB2 for z/OS version. If it is unsuccessful, there is no harm in not adding it to the mainframe version as it might be just a niche offering.
Evolution of new technology
Many of the System of Record emerging technologies listed in this blog will share a similar fate. Where they have not been implemented on the mainframe yet, they will be considered for the future based on their customer exploitation merits. You’ll notice I used a phrase: “not on the mainframe, yet”, a couple of times above. That’s because I believe it. Some of these emerging technologies will become ubiquitous and demand their place on the mainframe in much the same way as the DB2 technologies have evolved. Think about TCP/IP, Linux, Java, and XML that were once emerging technologies and are ubiquitously deployed on the Mainframe and within z/OS. Even Linux inside z/OS…at least some of it.
Same code. Different Container. Different Operations Model
With the adoption of open source and open programming interfaces, there are few programs that can’t be deployed on z/OS or the mainframe. But just because it can be done, doesn’t mean it should be done. For example, z/OS is branded as a Unix system because of the Unix System Services component. By that brand, it means it can support a VT100 character based terminal as an input device. So, using the vi editor, if you type a character, it would immediately get sent to the mainframe for processing. Type the next character and the same response. Move the mouse and you burn mainframe mips chasing it. Yes, that works, but it is a complete waste of mainframe processing. Capture the edit on a PC or smart device, using local processing. When done or the user hits enter, send the bulk of the input to the server to be saved and processed. Data processing is what the mainframe is about. The punch card and the 3270 terminal are “old school” systems of engagement. The mainframe has adapted to those interfaces as well. The z/OS Management Facility is a new web services based implementation that can augment or replace the “old school” 3270 command line functionality. New products, such as IBM zSecure and IBM Wave put a graphic front end on the mainframe. It is collaborative and hybrid deployments such as these vs. replacement of a legacy.
What’s your cluster look like?
The mainframe Parallel Sysplex solved clustered computing in a dramatically different fashion than commodity servers. Rather than separate data into smaller consumable chunks that are then spread across database servers that are then attached to clusters of application servers that need to have round robin workload balancing for some semblance of security, the mainframe did it different. They decided to share all data across their “cluster”. Each system has direct access to the data much like a SAN. This access is now Fiber Channel based, via the FICON protocol. It runs on the same fiber optics wiring as the FCP protocol, but it has better latency, security, error correction and redundancy. Shared by these clustered servers is the Coupling Facility. This is a separate mainframe server or logical partition with three functions:
- High speed communications (peer-to-peer) between the “cluster members”.
- Lock manager for read/write access to the shared data across the cluster.
- Data cache for the most recently used data (in memory) to avoid disk access for high volume transaction processing.
Commodity database server developers are beginning to make their own “coupling facilities” with a fraction of the functionality, performance, scale and reliability built into the mainframe Parallel Sysplex capabilities.
System Integrity
In 1973, IBM issued an integrity guarantee that any problems found in their code on the mainframe that could, and I’m paraphrasing, give an unauthorized person an undeserved authority, promote a program from user space to kernel space without authority or could manipulate or destroy data without authority would provide a fix at no charge, as quickly as possible. Recently, the guarantee was updated. But there is a reason for the guarantee and that’s baked into the hardware and software architecture of the mainframe. The hardware creates a boundary and set of instructions to manage the transition between user and kernel (system) processing. It also enforces boundaries on memory within the operating systems. As a result, a “buffer overflow” between user space and kernel space will be detected by the hardware. So in case there was poor programming on behalf of the operating system or middleware, the hardware is smart enough to detect the error and abnormally terminate the offending user program. It’s not to say the mainframe is hacker proof. Better stated, it is hacker resistant. The hardware architecture will detect and inhibit the majority of problems found from poor programming on commodity systems. In fact, execution of “portable” code on the mainframe has found a number of integrity problems that might have gone unnoticed on commodity software.
Multi-tenancy
Baked into the mainframe hardware and software is the goal that multiple applications, databases, and for that matter, operating systems, can run simultaneously without negatively impacting each other. The impact being integrity and performance based. The mainframe workload management capabilities for managing service levels and scale are legendary. Many more eggs can be put in a single basket. Far few servers need to be deployed. As PC servers became rampant in data centers, VMWARE came along and began to offer up to 80:1 reduction in the number of physical servers required to deploy workloads. Simultaneously, z/VM and Linux might offer an 800:1 reduction of the same workloads. Operational fiefdoms being what they are, an organization might be satisfied with the savings of an 80:1 reduction. Working collaboratively, there might be a 400:1 reduction in servers, with some on virtual blades and some of the mainframe.
Summary
This is not an either-or proposition, though organizationally, it might feel that way. Collaboration and sharing is at the foundation of the mainframe architecture. Now, through networks and multiple servers, that collaboration extends to Systems of Engagement.
A truly modern IT organization can realize the benefits of collaboration in application development, business resilience, time to deployment, operational risk and simply put, cost savings.
All of the above examples are to prove the point of the value of hybrid and collaborative computing. There are many offerings that provide similar value to those listed in this post.