Wow, I said it. It’s hard to admit for some of my peers, but looking back, there is a lot of truth to that sentiment. I’m not talking about traditional transaction processing used for insurance claims, point of sale, ATM’s, travel reservations, etc. That’s where money is being made and continues to be made, with many businesses leveraging mainframes as their System of Record.
No, that’s meant for folks that were and are interested in client/server deployments. Folks that wanted to use modern application development tools. Folks that wanted to incorporate multi-media and streaming into their workflows. These might be considered the System of Engagement today. Oh my goodness, the mainframe was not at all prepared to handle that work. Decisions were also made for departmental computers. Can you imagine a mainframe of that era in a closet? A closet? Where was the chilled water, the raised floor, the humongous air movers?

It was a traumatic change within IBM to begin the modernization of the platform and 1. keep it relevant to where it was having its “legacy” value (the prime objective) and 1A. make it relevant to capture new workloads. This was something tolerated, but not completely embraced at the IBM executive levels. Ignoring the success of “desktop computing” and new business opportunities, I always felt that the mainframe sales mantra was kind of the opposite of the famous Star Trek line: To boldly go where we have already sold before. So the real goal appeared to be to keep our current mainframe customers happy.
The mainframe is a dinosaur. The mainframe is dead
There were voices, everywhere, saying the mainframe was dead, it’s a dinosaur. It chilled the hearts and minds of senior IBM executives too. There was a “new breed” of executive that wanted to look and grow new business lines, like the PC Server and Power Systems. Where did their funding come from? The profit of the mainframe. But as a result, mainframe R&D budgets were challenged. And even within the mainframe, as growth opportunities were considered, the development budget was spread even thinner across a wider variety of efforts. Some believed it was a cash cow, from which new opportunities should be funded. And then there were the mainframe believers that had to fight “the new status quo” to maintain their budgets. I could go on and on about these political battles inside IBM. There’s some TMZ quality stuff, but not what I want to discuss here.
Now, if you don’t want to read the story about what changes were made and how they were made, you can skip to the Summary of how bad it was and how good it has become.
The long road toward making the mainframe relevant to new workloads
Instead, I’d like to tell you about the changes that were made to make the platform relevant to new business opportunities. In the process, the positioning of the mainframe changed. It’s still a terrific System of Record, but now, unlike the 1990’s, it can be a viable System of Engagement for many functions, but not all. Because if I said all functions, I’d be lying every time I mentioned hybrid computing!
Let’s start with a big mainframe app that made the decision to go “all distributed” and never looked back. That hadas much to do with money as it did with technology.
Dassault never looks back. Goodbye mainframe
Dassault System’s CATIA application – a CAD/CAM – engineering modeling/rendering application. They were charging $8K a user for the MVS version. Each user had a specially built 3270 Graphics Adaptor for model renderings on a “green screen”.
There were so many instructions required to do the renderings that each terminal had it’s own hardware interface. At the time, there were only 4096 interfaces (called Unit Control Blocks – UCB) on the system. As more engineers created modern airplanes, the customers had to buy more systems, which were not cheap to acquire, nor operate. Ultimately, the z/OS operating system eliminated the constraint on the number of UCBs, which would have greatly helped CATIA customers, but had the added benefit of helping all customers when Parallel Sysplex was introduced later.
CATIA grew bored with the proprietary 3270 GA box as their graphics rendering device. They wanted color and simpler graphics.
This is just what the UNIX community was demonstrating. So they created a new product, based on AIX. They thought the UNIX based version should charge about $10K a seat. Some cooler graphics were worth the price, but not too far off the current customer price. They did a market study. They found other UNIX based engineering programs were getting about $25K a seat And those systems were selling well. What a profit margin! So they decided to charge $22K a seat, in order to undercut their competitors. They also yelled from the rooftops “the mainframe is dead” in order to transition to the new model, but more importantly, the new revenue and profit stream. What was surprising to me was that Dassault was partially owned by IBM. My job was to talk to the “chief yeller” and convince them of the “new mainframe strategy” which was still vapor ware, from their perspective. All requests to stay on the mainframe fell on deaf ears, and rightfully so, in hindsight.
SAP tells IBM what’s wrong with the mainframe
A “big mainframe” app that transitioned to commodity systems was from SAP, which was mainly a bunch of ex-IBMers that had a really good idea. SAP R/2 was created with a mainframe back end application and database server which also drove the green screen terminal front ends.
SAP R/3, the next major version, was a “client/server” app that was all about the end user experience (GUI) and commodity server deployment models. It didn’t run on the mainframe when it first came out. SAP was one of the voices bragging about the “death of the mainframe” in order to transition customers to their new product. It took years of negotiations and modernization of the mainframe infrastructure and pricing changes for SAP R/3 to “return” to the mainframe, but it was only a partial return….The Database, entirely, and then the data access methods and some of the applications. The presentation layer has expanded beyond the desktop into mobile and web services. The original application programming language remains the same, though it has been augmented with Java.
Let’s peel the onion and look into modernization specifically for SAP R/3. In my opinion, it was that application, or better stated, that company that forced IBM to change the mainframe. IBM wanted new workloads. Here was a big one that took business away…Let’s win it back.
Network Performance and System Integrity
First, client/server was based on the internet and local area networks. They were rapidly transitioning to TCP/IP hosted networks – an open network. IBM was still stuck on SNA, it’s proprietary network that was actually a de facto industry standard as most systems could interoperate with it. Today, SNA applications can run over TCP/IP….it’s about layering, but that’s too detailed. An implementation of TCP/IP for MVS is created. Check the box. Done. Well, wait a minute…how well does it perform, SAP asks. It takes about 186,000 instructions to send a small chunk of data out and receive the acknowledgement of successful delivery. By contrast, it takes AIX about 18,000 instructions to do the same. So MVS is about 10 times slower communicating with TCP/IP than other platforms. Well, no it’s not. The SAP R/3 application is very chatty. The application server makes a network connection to the database server on the mainframe. For each end user request that ends up making a database call, there are actually 26 send/receive pairs for each transaction. So the overall pathlength is 260 times worse than AIX for a single SAP transaction. At the mainframe hardware and software price levels, that isn’t going to sell well. I also made a joke of this at the time. What’s Lassie, RinTinTin, Benji and TCP/IP on MVS?
Three movie stars and a dog. Drum roll please. This was a bad situation. Unfortunately, this joke lasted several years. A lot of effort went into looking at alternative implementations.
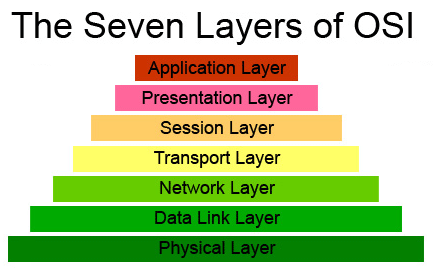
Anytime there is a network, data must move from one system to another system. In a terminal environment, such as a 3270 screen update, it might only be 100 bytes of data get transmitted. But a video could be millions of bytes. IBM, from it’s outset, has been historically great at creating architectures. Some architectures have layers of functionality. Communications or networking architectures are famous for the seven layer diagram,
 where each layer has an architectural purpose. Application layer, transport layer, session and network layers being a subset. IBM has an image processing application originally developed for medical records called Imageplus. The performance of image processing (and later streaming) over the network, because of the rigidity and adherence to the layers of architecture by the original code base, was horrendous. The physical image was COPIED TWELVE times, once for each layer and a few times within the application, as it traveled through the operating system. Eventually, the networking software was modified so that it could copy the data from the application buffers directly to the transmission wires after a quick test of the applications data integrity (aka make sure there would be no buffer overflows or attempt by an application to send system or privileged data that they didn’t have authority or “need to know”. This data integrity testing, by the way, is inherent throughout the mainframe operating systems and middleware).
where each layer has an architectural purpose. Application layer, transport layer, session and network layers being a subset. IBM has an image processing application originally developed for medical records called Imageplus. The performance of image processing (and later streaming) over the network, because of the rigidity and adherence to the layers of architecture by the original code base, was horrendous. The physical image was COPIED TWELVE times, once for each layer and a few times within the application, as it traveled through the operating system. Eventually, the networking software was modified so that it could copy the data from the application buffers directly to the transmission wires after a quick test of the applications data integrity (aka make sure there would be no buffer overflows or attempt by an application to send system or privileged data that they didn’t have authority or “need to know”. This data integrity testing, by the way, is inherent throughout the mainframe operating systems and middleware).
So the Imageplus benchmark was also critical to understanding how to re-write the TCP/IP stack. If the system knew the SAP Application server was running on an AIX server that was channel attached to the mainframe, the new performance was 5,000 instructions. (Didn’t need to do some network error handling nor routing and this saved instructions). If the Application server was attached via a router, then it was 10,000 instructions. Hallelujah….we were better than the rest of the world…..
Data Character Translation
Not yet, says SAP. Those desktops, those application servers on Windows and UNIX/AIX? They like to read and present data in ASCII format. Your mainframe and DB2? They like to process data in EBCDIC format. It takes seven instructions to translate each byte. So all that network gain that was just achieved is lost by data translation. As a result, effort is put into the path length of data translation. Eventually, it gets down to three instructions per character. With the network savings, this is roughly equivalent, end to end of a commodity system performance. With price/performance, it’s still not good enough. As a result, the mainframe hardware, operating system and DB2 middleware are changed to natively support unicode characters, wide characters (for character based languages) and many other code pages. There was, and is, no longer a penalty for code conversion. Finally, after several years of work, SAP R/3 sales of hybrid computing began.
New workload pricing
But the transition isn’t complete. The introduction of Linux on System z leads one to believe that the mainframe is a viable application server. Not so fast, says SAP. IBM charges software by the MIPS or capacity of the ENTIRE machine. So if a customer adds one processor to run Linux on a mainframe that has 9 existing processors, the Linux license charge would be for 10 processors worth of work vs. the single processor that is executing. I’m going to rapidly jump ahead, but specialty engines were created such that new workloads, such as Linux, JAVA on z/OS, distributed connections to z/OS databases, some z/OS system utilities and more are charged by the actual engine or capacity of the workload vs. the entire capacity of the machine. Finally, incremental workloads could be added to the platform at or near commodity prices for the equivalent work. But we’re still not done with this evolution in hybrid computing.
Stop copying data. Share memory instead
Avoiding data moves was critical to the success of the “new” TCP/IP within z/OS. So next, the same concept is applied WITHIN the mainframe. And this takes several iterations with continuing benefit.
In a Blade server or rack mounted system, a special back plane or Top of Rack switch may be deployed so that communications within a ‘server box’ can go point to point, ala the mainframe channel to channel interface and avoid router overhead. Under z/VM with hundreds of Linux images running and then z/VM to z/OS within the same physical server, IBM created the hipersocket which uses dedicated hardware memory, instead of wires, to facilitate intra-physical server communications. The most recent announcement upgraded the hipersocket technology to leverage RDMA memory that can be shared between server images so that only a pointer to the data is transmitted. Each system can have direct access and eliminate intra-server copying of the data.
Increased capacity and memory available for new workloads
All of the above mentioned activities result in fewer data moves within the operating systems, virtualization layers and hardware servers themselves. This avoids instructions, real memory and latency required to do data moves. This allows the processors and memory to be available for other workloads. This allows greater scale of the environment. And because the mainframe has been doing this for over 40 years as a balanced architecture across instructions, memory, networks and data, instruction pipe lining, many levels of memory caching and more, it is capable of putting, colloquially, 10 pounds of “stuff” in a 5 pound bag without fear of breaking. Said another way, there is no fear in running the system at 100% utilization for very long periods of time.
The “Legacy” workloads get modern as well
So that’s just a snippet of the technology that went into “modernizing” the mainframe for new workloads. There is significant other infrastructure, such as the Parallel Sysplex, Geographically Dispersed Parallel Sysplex (GDPS), evolution from BiPolar to CMOS technology, reductions in cooling, electricity and floor space, packaging of “spare” parts in the box for fail over/fault avoidance and on demand deployment for capacity upgrades and more that made the mainframe better for traditional workloads, and over time, those benefits have applied to the new workloads as well.
But then, how much does it cost?
Historically, the mainframe has been considered an expensive alternative to “commodity” platforms that are “just good enough”. Much has been done to change the pricing structures.
Technology Dividends
Since the introduction of OS/390, IBM and other vendors have been providing tech dividends such that the price/mips has decreased regularly and with most new processor introductions.
Capacity Backup
The “z” in System z, stands for Zero down time. While not reality, it is a goal, both at the technical level and through software license charges. IBM introduced Capacity BackUP (CBU) pricing for backup or disaster recovery servers. A fraction of the production price is paid for the hardware server and no software license charges are paid. Many other vendors have accepted this model as well. Why? Because a business isn’t getting any productive work out of the backup servers. When production work moves over to the CBU server, then the software license charges transfer to that machine. A business may do several “fail overs” a year, to test recovery operations without incurring a license charge. When compared to “commodity” servers, this can be a tremendous savings. In those environments, multiple servers may be required and each of those will be charged a production license fee.
Development pricing
If a business wants to get more workloads, then it needs to cater to application developers. Those developers need a sandbox or low priced system to create that code. Unfortunately, software license charges being as they are, all MIPS on the mainframe were created equal and treated as production. Rational was a brand acquired by IBM. They had created some fantastic tools that worked across platforms and now included OS/390 and later z/OS. Those applications would require CICS, IMS, DB2 and other vendor middleware as the target production environment. However, IBM was charging the same price for the production licenses. Most other vendors, including Microsoft, Sun, Oracle and HP were giving away the run times when they sold their development tools. As a result, the mainframe was not targeted by most vendors as a viable deployment platform because the “cost of entry” was way too high.
IBM finally released a mainframe architecture that ran on PC and Power servers – the z Personal Developer Tool (zPDT) to vendors. This created a competitive cost for vendor developers to target the mainframe as a production platform. It was several years later that IBM decided to make this available to businesses or customers. Finally, there was a common tool set, Rational Developer and free run times and test environments that were priced competitively with “desktop” development tools. Better yet, a developer could “take a mainframe home” with them, as the zPDT could run on a Thinkpad laptop.
Parallel Sysplex pricing
Clustering computers is an important way to scale. IBM invented the Parallel Sysplex architecture that accomplished three things, with two being a huge differentiator from “commodity” server clustering.
- Load balancing work across the cluster
- Shared Lock management of database and file records across the cluster
- Shared cache of the database and file records across the cluster, allowing all cluster members to have direct access to the data.
The direct access of shared locks and data cache allow additional servers to be added to the cluster without having to reorganization or partition the data. The performance is such that there is linear scalability as each new cluster member is added to a maximum of 32 systems.
Software was then discounted for customers that chose to use the Parallel Sysplex as a clustered model over a multi system model that had non shared data.
New workload pricing
This was discussed earlier. The net is that specialty engines were defined that allowed no software license charges or deeply discounted license charges for Java, Linux and other workloads.
Hybrid Computing pricing
With the zEnterprise servers, the mainframe added the ability to have direct attachment to an IBM Bladecenter and in the process, have a dedicated communications channel and a dedicated management channel for these two devices. I already described how performance can improve when channel attached when discussing the SAP R/3 deployment between AIX and z/OS.
The IBM Data Application Accelerator (IDAA) is a query server, running on x86 blades that can get direct access to DB2 on z/OS. By shipping queries over to the IDAA server, read/write operations can continue on z/OS while read only performance of the query can be parallelized across multiple x86 engines and see performance improvements that could be 300 to 1000 times better than if run on z/OS. More importantly, the IDAA is “just an engine”. Security of the database and audit remains within DB2 for z/OS. Data copies over the network can be avoided. Some copying is inevitable, but flash copies can be made in moments, instead of long running data extract, transform and loads (ETL) to other platforms. This provides a significant advantage to completing near real time analytics and enables new decisions to be made, prior to completion of a transaction. There are too many cost savings to mention, but some are: less disk space, faster response time, improved security, better scale, less network bandwidth consumed, etc.
Mobile pricing
In the 1960’s and continuing through the early 1980’s, it was agents of a business that executed transactions. Travel agents, Bank Tellers, Claims adminstrators, ATMs and Point of Sale terminals. The consumer watched. These transactions were typically short, easily measured and predictable. The majority of the transactions occurred during business hours, such as 9AM to 5PM. Hardware and software were priced for the size of the machine dictated the overall software license charges.
The “Internet of things” has changed that. Consumers can now do things on their own, where an agent was previously required. They can start a claim, transfer money, deposit a check, buy tickets to performances and for travel. They can do this at any time of the day or night. They can query prices as often as they wish, waiting for the “sale price” to be good enough to actually purchase something. This is dramatically grown the number of transactions being executed and kept the Systems of Engagement and Systems of Record up around the clock. Any down time means potential and real loss of business. In April of 2014, IBM introduced the Mobile price usage to provide a discount for these type of consumer issued transactions. The goal is to make the monthly pricing more predictable and comparable with “commodity” platforms.
Summary
How bad it was (1990’s)
Let’s review how bad the mainframe was back in the early 1990’s.
- Water cooled, very large, heavy servers with large amounts of electricity and cooling required.
- An Internet network that was horrendously slow at the hardware and software levels.
- A Green screen Command oriented interface (similar to the DOS Shell that lived a very short while on PCs). Yes, you could “screen scrape” to make it look more graphic, but many considered that “lipstick on a pig”.
- A communication architecture that was inherently inefficient as it copied data between system components, many times, before it went on “the wire”. In PC LAN terms, it was a Ring 4 implementation (and worse) instead of Ring 0.
- The wrong character set was used: EBCDIC, which required software changes and data conversions to and from ASCII or Unicode.
- Expensive software licenses for production and development.
- Proprietary, green screen oriented, development tools
- Proprietary programming interfaces
- Lack of Commercial Off the Shelf (COTS) new workloads
How much better it is today
- Comparably sized servers to commodity systems that use less electricity and cooling.
- An incredibly faster Internet connection for inter-system, intra-system and intra-cluster communications.
- While the command line interface is still available, a web service oriented management interface is now available.
- A communication interface that passes pointers to data and shares the data rather than copying it within a system image, across virtual system images and across a cluster of systems.
- Adoption of Unicode, ASCII and EBCDIC as base characters simplifies data consolidation on z.
- Technology dividends and a wide variety of pricing options make the TCO and TCA of System z competitive with commodity servers
- Single, cross platform tooling from Rational that includes mainframes, UNIX/Linux, Windows and Mobile systems (via the Worklight acquisition)
- Portability of applications within z/OS and Linux in a variety of open languages
- A far broader range of COTS software is available for Linux on z and z/OS
Some additional items that are better than commodity servers
- Shared data access, with integrity, scale and resilience, across systems
- Shared Analytics and Transaction Processing to a single database (that can be shared across a cluster), while maintaining Service Level Agreements
- Hacker resistant (not Hacker proof) architecture that inhibits data and buffer overlays. The System Integrity guarantee has been in place since 1973.
- Capacity Backup licensing and acquisition dramatically reduce Disaster Recovery costs and procedures.
- System z hardware avoids 80% of the errors that might occur in a PC server environment. No down time nor failover would occur. System z software and hardware work together to drive System availability to 99.999%.
- Workload management of thousands of applications and hundreds of thousands of client connections enables dramatic cost savings over alternative servers.
- Incremental additions of software workloads without the need to install new hardware due to on board “spares” available to be turned on, on demand.
Summary
If you haven’t considered a mainframe in the last 20 years, it’s quite understandable. But if you don’t start reconsidering it today, you are making a fundamental mistake.
The modern mainframe is greatly simplified from where I began 40 years ago. I’m happy to say I may have had a little bit to do with that 😉 Happy programming.